1.互联网起源
1969 年起源 加利福尼亚大学洛杉矶分校 斯坦福大学 加利福尼亚大学 犹他州大学
互联网——Internet(因特网、英特网),网际网路
1989 年,欧洲粒子物理研究所——协议(格式)WWW(world wide web)万维网
1991 年,普及应用
查看 ip:
- mac:ifconfig
- window:pconfig
图灵:计算机科学之父
冯诺依曼:计算机之父
手机和平板也算计算机——冯诺依曼式计算机
冯诺依曼式计算机一一冯诺依曼(面试题)
运算器:
CPU ,GPU(显卡)
存储器:
内存(断电数据清空,读写速度快),
硬盘(辅存):(数据可以持久化,读写速度,相对较慢)
控制器:
主板上的一些器件
输入设备:
键盘,鼠标,麦克风,网口
输出设备:
显示器,耳机,网口
2. 局域网
局域网
局域网:跨局域网不能访问
邓哥和成哥连接共同的路由器依旧不能互相访问?——ip
IP 地址格式:分为四个段:xxx.xxx.xxx.xxx。每个段 0-255,每个段都是由 8 个 0/1 组成的。
IP 地址分类:一个 IP 地址分为两个部分:网络 ID, 主机 ID
A 类:0.0.0.0-127.255.255.255(一个网络能有 1600+万台)
B 类:128.0.0.0-191.255.255.255
C 类:192.0.0.0-223.255.255.255(私有网络)
D 类:多播地址
E 类:
127.0.0.1 代表本机
0.0.0.0 代表不知道 ip,默认打到自己本机上
3. ip 地址与公网
ip 地址
4. 域名和 DNS 解析过程
域名与 DNS 解析
www.baidu.com叫做域名
问:能通过域名直接访问到一台机器吗?答:不可以的。网络只认得 ip 地址
实际上时用域名和 IP 形成对应关系。
首先,计算机是不知道域名对应的 IP 的。
问路由器,如果路由器认识这个域名,就返回一个 IP,然后计算机访问这个 IP。如果路由器不认识,他就问上一层路由器。
如果问到了城市这个级别的路由器的时候,DNS 服务器。
如果 DNS 服务器不认识这个域名,继续向上级 DNS 服务器查找。
互联网建立的时候,13 台总的 DNS 服务器。
当向浏览器的地址栏中输入一个 url 按回车之后,网络中都会发生什么?
比如输入的是 123.xyz
- 看浏览器的缓存。
- 本机 host。
C:windows/system32/drivers/etc/host
127.0.0.1 默认指的是当前这台机器 localhost
0.0.0.0:不知道 IP 地址,默认自己本机
- 家里路由器
- 上级路由、城市的 LDNS 服务器
- 继续向上级的 DNS 服务器找。
- globalDNS 服务器。(一定有)
在浏览器地址栏中输入一个页面地址,按下回车键后发生了什么?
浏览器将 url 地址补充完整:没有书写协议,添加上协议
浏览器对 url 地址进行 url 编码:如果 url 地址中出现非 ASCII 字符,则浏览器会对其进行编码
浏览器构造一个没有消息体的 GET 请求,发送至服务器,等待服务器的响应,此时浏览器标签页往往会出现一个等待的图标
服务器接收到请求,将一个 HTML 页面代码组装到消息体中,响应给浏览器
浏览器拿到服务器的响应后,丢弃掉当前页面,开始渲染消息体的 html 代码。浏览器之所以直到这是一个 html 代码,是因为服务器的响应头指定了消息类型为 text/html
浏览器在渲染页面的过程中,发现有其他的嵌入资源,如 CSS、JS、图片等
浏览器使用不阻塞渲染的方式,重新向服务器发送对该资源的请求,拿到响应结果后根据 Content-Type 做相应处理
当所有的资源都已下载并处理后,浏览器触发 window.onload 事件
答案:
客户端发给 DNS(域名解析服务器)服务器 查询对应的 ip (应用层)
客户端向 ip 对应的服务器进行建立连接(三次握手) (建立连接的发起是在传输层)
建立好连接之后 进行数据传递 传输层
数据传递完成 断开连接 (四次挥手)传输层
渲染页面 —— 文件按行解析执行
解析执行的过程中生成 DOM 树 接着根据 css 生成 CSS 树
合并成为 渲染树
根据渲染树开始渲染页面 展示出来
遇到 script 标签(会执行 script 标签里面的代码)会阻碍后面的代码执行
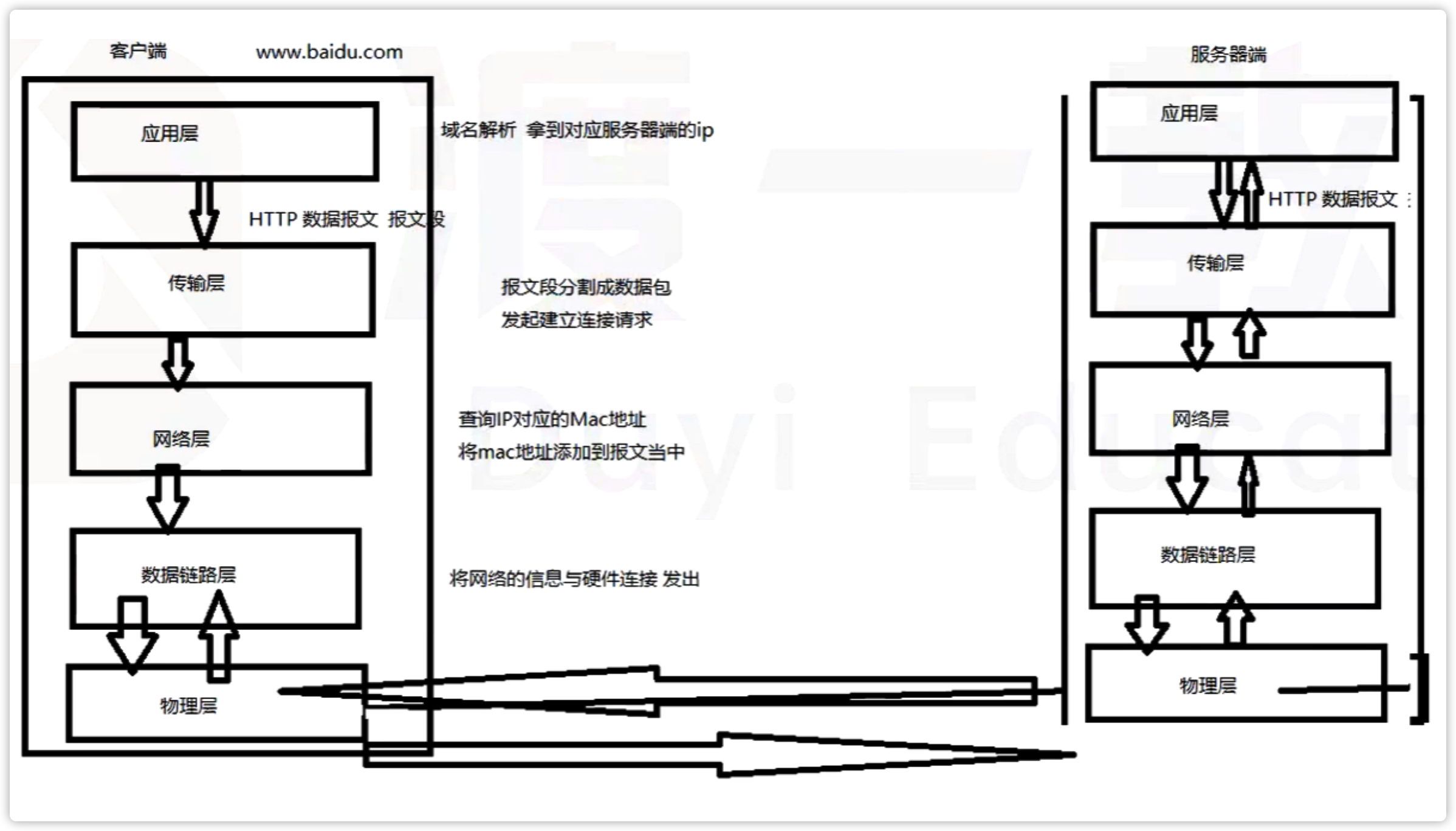
思考:
本机 host 不缓存,没有权限往里面写,用户自己可以写,可以篡改域名,浏览器缓存
所以输入 url 按下回车:至少往外发出 2 个信息
- 通过域名找到 ip
- 然后访问 ip
5. 五层网络模型

物理层传输方式:
UDP 与 TCP 区别:
TCP 协议:安全可靠,发出请求在线等
UDP 协议:发出请求不管了
url 不一定都展示在地址栏里面
发出去的是 http 协议,伴随着 TCP,IP 协议
比如要想传送一个 hello,但是根据 http 协议,我不能直接传,需要有一个格式
http 协议格式:
HTTP 协议分为两个部分:
请求:Request
请求头(Request Headers)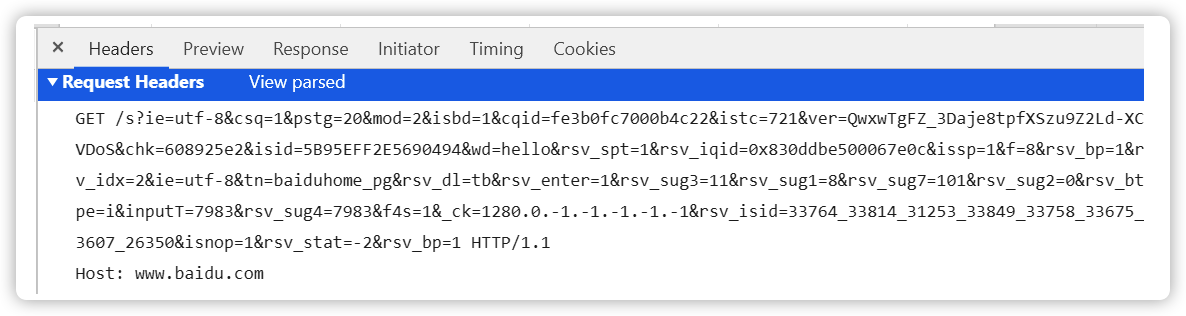
请求头:请求方式 路径 协议版本
两种请常用的请求方式:GET POST,还有 HEAD, PUT, DELETE
响应:Response
要想解析 hello,要经过层层包装加密(自上而下),层层解析(自下而上)的过程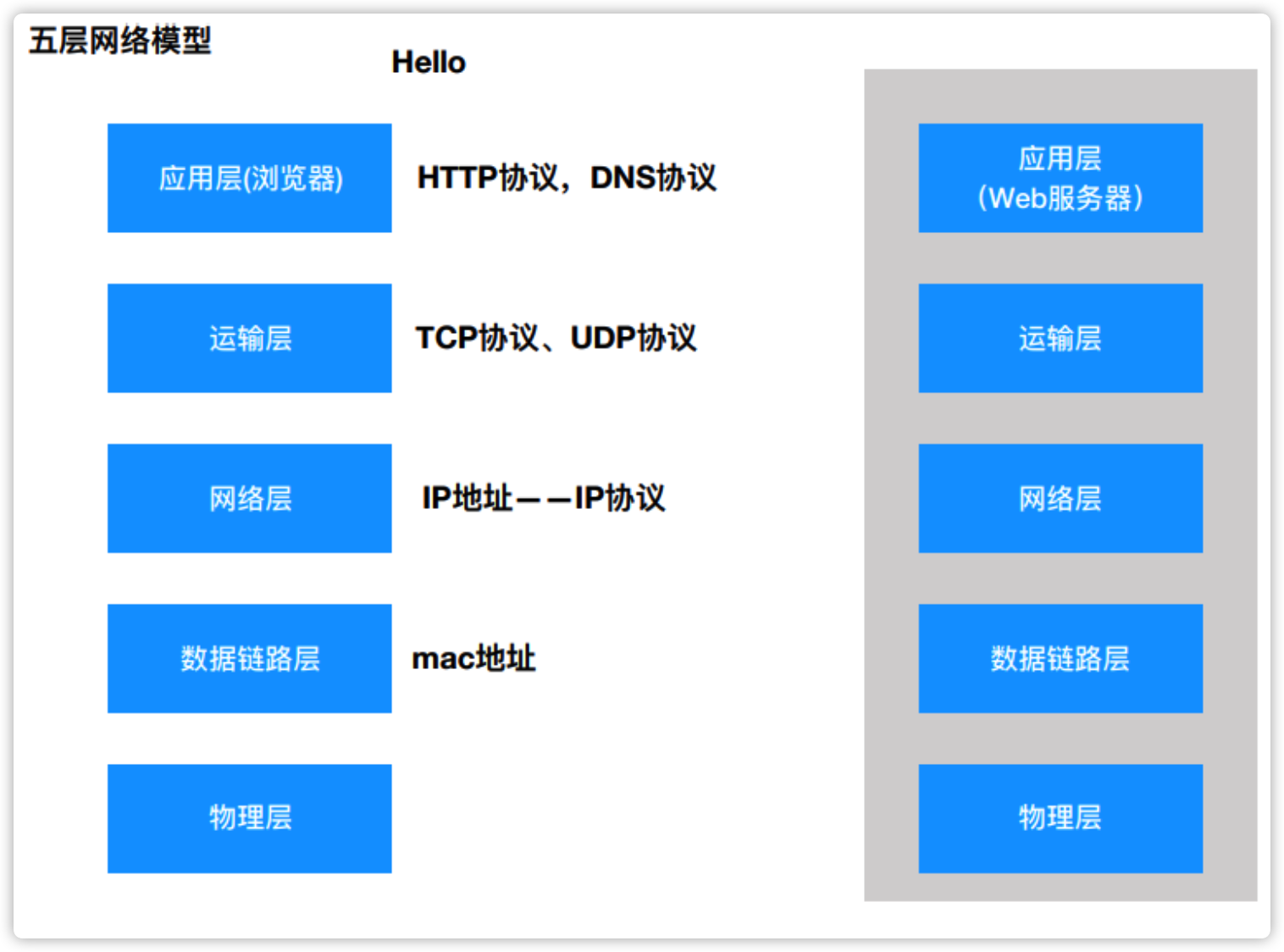
6. 简述 HTTP 协议
请求
两个部分:请求头、请求体
HTTP 源码格式:POST/path?a=1&b=2 HTTP1.1
Request Headers
- Host: www.baidu.com
- Connection: keep-alive
- User-Agent: asdasdasd
- Cookie
GET 特点:web 环境下的 http ,请求的参数都在 url 里
响应:
两个部分:响应头、数据体
响应头:协议版本 状态码 message
属性:值
Cache-Control:max-age=864000 在一天内相同的请求就会取缓存
7. GET POST 区别
- 是基于什么前提的?如果什么前提都没有,不使用任何规范,只考虑语法和理论上的 HTTP 协议。
GET 和 POST 几乎没有什么区别,只有名字不一样。
- 如果是基于 RFC 规范的。(RFC 组织来决定是否收纳一些协议规范)
(1)理论上的(Specification) : GET 和 POST 具有相同语法的,但是有不同的语义。get 是用来获取数据的,post 是用来发送数据的,其他方面没有区别。
(2)实现上的(lmplementation) ︰各种浏览器(web 环境下的),就是这个规范的实现者。
所以才有了常见的那些不同
- GET 的数据在 URL 是可见的。POST 请求不显示在 URL 中。
- GET 对长度是有限制的,POST 长度是无限的。
- GET 请求的数据可以收藏为书签,POST 请求到的数据不可收藏为书签。
- GET 请求后,按后退按钮、刷新按钮无影响,POST 数据会被重新提交。
- GET 编码类型:application/x-www-form-url,
POST 的编码类型:有很多种。
encodeapplication/x-www-form-urlencoded 加密的
multipart/form-data(传输文件的一些信息:POST 这种就可以发送文件)
- GET 历史参数会被保留在浏览器里,POST 不会保存在浏览器中的。
- GET 只允许 ASCll。POST 没有编码限制,允许发二进制的。
- GET 与 POST 相比,GET 安全性较差,GET 所发的数据是 URL 的一部分,POST 都在数据体里。但是HTTP 协议是种明文协议,都不安全。
纠正想法:地址栏!=URL,URL 不一定都展示在地址栏里面
请求方式 : 为了告知服务器请求意图是什么
- GET : 获取资源
- POST:传输实体主体(详细信息)
- PUT: 传输文件 (使用的场景: 1. 传递文件 2. 修改实体数据)
- DELETE : 删除文件
- HEAD: 获得报文首部 (不传递里面的数据)
- OPTIONS:询问支持的方式
详细版:
1 GET 请求指定的页面信息,并返回实体主体。
2 HEAD 类似于 GET 请求,只不过返回的响应中没有具体的内容,用于获取报头
3 POST 向指定资源提交数据进行处理请求(例如提交表单或者上传文件)。数据被包含在请求体中。 POST 请求可能会导致新的资源的建立和/或已有资源的修改。
4 PUT 从客户端向服务器传送的数据取代指定的文档的内容。
5 DELETE 请求服务器删除指定的页面。
6 CONNECT HTTP/1.1 协议中预留给能够将连接改为管道方式的代理服务器。
7 OPTIONS 允许客户端查看服务器的性能。
8 TRACE 回显服务器收到的请求,主要用于测试或诊断。
9 PATCH 是对 PUT 方法的补充,用来对已知资源进行局部更新 。
get 和 post 的区别
- get 请求会把数据拼接在地址栏当中 post 不会, 会放在请求体当中
- get 请求的数据量较小(地址栏大小限制)大约为 4kb post 请求的数据量较大 也有限制 5m
- get 请求会有缓存(数据也会被缓存下来) post 不会
- post 相对安全
- 编码类型: get 请求数据只能用 ASCII 编码 post 请求没有限制
POST 一般可以发送什么类型的文件,数据处理的问题
- 文本、图片、视频、音频等都可以
- text/image/audio/ 或 application/json 等
8. cookie 与 session
Cookie 与 Session
- 如果我们用 JS 的变量来存数据,那么在页面关闭的时候,数据就消失了。
- 保持登录状态是怎么做到的呢?
按照正常的 HTTP 协议来说,是做不到的。因为 HTTP 协议,上下文无关协议。
- 所以说前端页面上,有可以持久化存储数据的东西。一旦登录成功,我就记载在这个里面。
Cookie 是有限制的,自己只能往自己的域名下种 cookie。
Cookie 是存在浏览器里的,不是存在某个页面上的。是可以长期存储的。Cookie 即使是保存在浏览器里,也 是存放在不同的域名下的。
自动登录过程
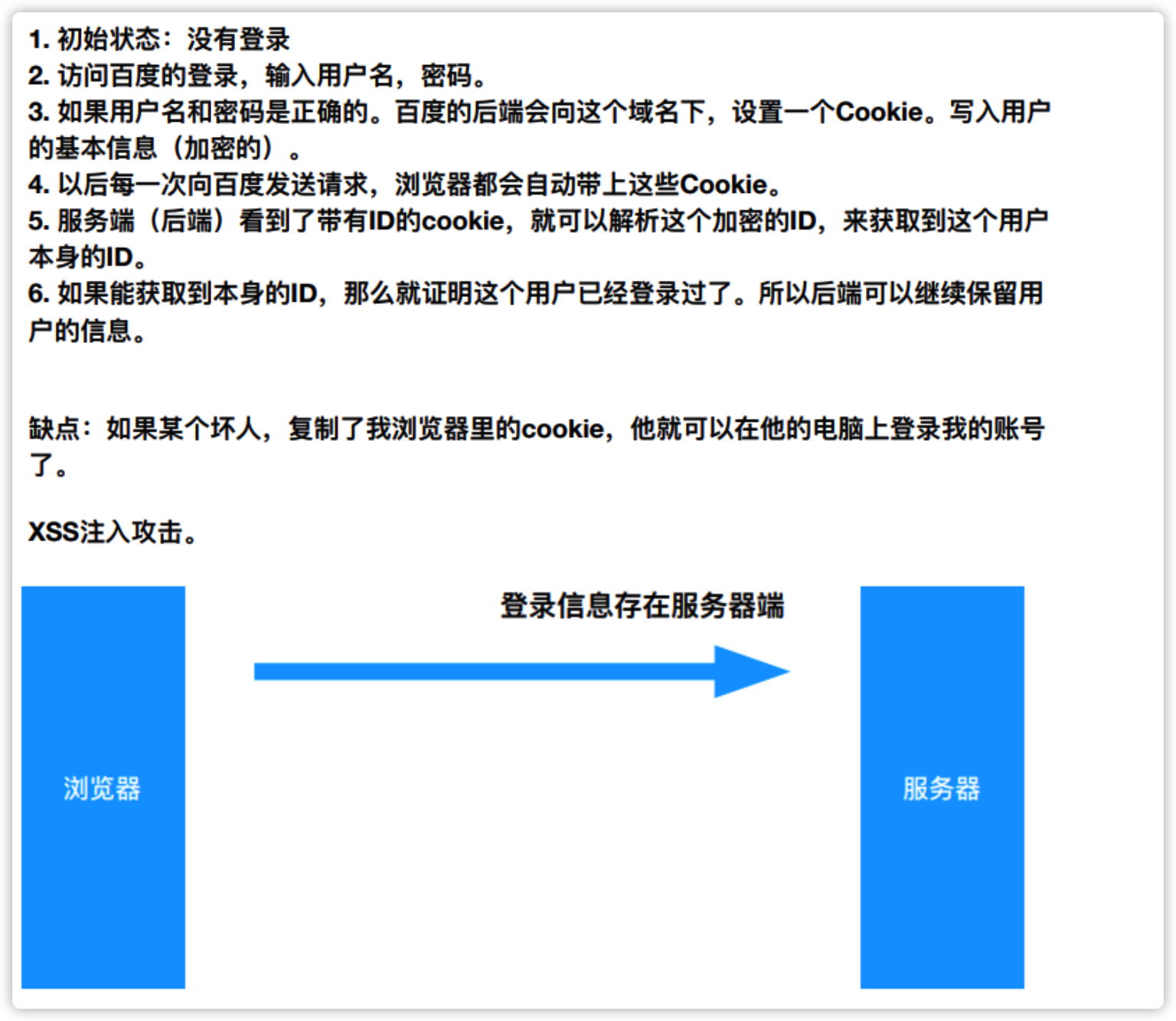

不同 JS 文件不能互相访问
<script src="demo.js"></script>
<script>
console.log(a);
</script>自己只能往自己的域名下种 cookie;
cookie 可以跨页面,关闭页面不会消失,不能跨域存储
cookie 信息存在浏览器上,session 信息存在服务器上
9. 发送网络请求
方式:
- 在浏览器直接输入网址(无法用代码控制)
- location.herf=”url”,可以发出网络请求,但是页面会跳转(页面会跳转)
- 带有 src 属性的标签。请求是可以发出的,服务端可以处理,也可以返回,但是返回之后能否被应用还要看浏览器 img,script(页面无法处理返回结果)
- 带有 href 属性的标签,请求是可以发出的,服务端可以处理,也可以返回,但是返回之后能否被应用还要看浏览器 link(页面无法处理返回结果)
- 带有 action 属性的标签。比如 form 表单,也可以向后端发出网络请求,但是 form 表单发出请求后也会页面跳转(页面会跳转)
<form action="www.taobao.com" method="get">
<input type="text" name="name" />
<input type="text" name="age" />
<input type="submit" value="提交" />
</form>希望有一种方式,可以用代码控制,页面不会跳转,服务器返回的结果我可以用 js 继续处理
- ajax
// 请求要素
// (1).请求方式:get post
// (2).url
var xhr = null;
if (window.XMLHttpRequest) {
xhr = new XMLHttpRequest();
} else {
xhr = new ActiveXObject("Microsoft.XMLHttp"); // 兼容IE6
}
xhr.open("get", "http://developer.duyiedu.com/edu/testAjax");
xhr.send(); // No 'Access-Control-Allow-Origin' header is present on the requested resource.跨域10. 跨域
跨域发生在浏览器(接受的时候),不是服务器


演示:
新的接口,后端设置了 Access-Control-Allow-Origin,就可以跨域了
var xhr = null;
if (window.XMLHttpRequest) {
xhr = new XMLHttpRequest();
} else {
xhr = new ActiveXObject("Microsoft.XMLHttp");
}
xhr.open("get", "http://developer.duyiedu.com/edu/testAjaxCrossOrigin"); //初始化建立连接JSONP
var xhr = null;
if (window.XMLHttpRequest) {
xhr = new XMLHttpRequest();
} else {
xhr = new ActiveXObject("Microsoft.XMLHttp");
}
xhr.open("get", "http://developer.duyiedu.com/edu/testJsonP?callback=asd");11. 页面正确打开方式
两个概念

三种编辑器的 server 插件安装
12. 原生 JS 发送 ajax
var xhr = null;
if (window.XMLHttpRequest) {
xhr = new XMLHttpRequest();
} else {
xhr = new ActiveXObject("Microsoft.XMLHttp");
}
console.log(xhr.readyState); //刚创建时候readyState为0
xhr.open("get", "http://developer.duyiedu.com/edu/testAjaxCrossOrigin");
console.log(xhr.readyState); //1
xhr.send(); //执行发送
console.log(xhr.readyState); //1,发送之后状态没变
xhr.onreadystatechange = function () {
//当readystate变化时候,就执行
// readyState == 4表示请求已完成,已经接收到数据
console.log(xhr.readyState);
};readyState == 4 表示请求已完成,已经接收到数据
xhr.onreadystatechange = function () {
if (xhr.readyState == 4 && xhr.status == 200) {
alert(xhr.responseText);
}
};HTTP 状态码
2 表示成功
3 表示重定向(迁移的新地址)
4 表示客户端错误,404 页面没找到。
5 表示服务端错误
<script>
xhr.onreadystatechange = function () {
//readyState == 4表示请求完成,已经接收到数据。
//status == 200 网络请求,结果都会有一个状态码。来表示这个请求是否正常
if (xhr.readyState == 4 && xhr.status == 200) {
document.getElementById("test").innerText = xhr.responseText; // 可以展示在页面上
var data = JSON.parse(xhr.responseText); // 转成JSON
console.log(data);
}
};
</script>以上方法不规范:网速很快,send 瞬间返回结果,function 还没完成,会返回 null。
改进:send()放在后面
总结:原生 JS 发送 ajax
var xhr = null;
if (window.XMLHttpRequest) {
xhr = new XMLHttpRequest();
} else {
xhr = new ActiveXObject("Microsoft.XMLHttp"); //兼容IE6
}
console.log(xhr.readyState);
xhr.open("get", "http://developer.duyiedu.com/edu/testAjaxCrossOrigin", true);
console.log(xhr.readyState);
xhr.onreadystatechange = function () {
if (xhr.readyState == 4 && xhr.status == 200) {
document.getElementById("test").innerText = xhr.responseText;
var data = JSON.parse(xhr.responseText);
console.log(data);
}
};
xhr.send(); //如果open第三个参数传true,或者不传,为异步模式。会导致后面的同步代码先执行。
// 如果传false,为同步模式。
console.log("===="); // 先执行的
console.log("+++"); // 先执行的在计算机的世界里,异步与同步和现实世界中是相反的。
在计算机的世界里,同步表示串行。异步表示同时进行。可以理解为同线程和异线程。
13. JSONP 使用与特性
jsonp 格式哪里特殊?
- 发送的时候,会带上一个参数 callback(回调)
- 返回的结果不是 json
- callback 的名 + ( + json + );
- jsonp 跨域,只能使用 get 方法,如果我们设置的是 post 方法,jquery 会自动转为 get 方法。
是不是在 jsonp 里面我只能使用 get 方法?是不是我设置的 post 方法都会转为 get 方法?
不是。jquery 会先判断是否同源,如果同源,那么设置的是 get 就是 get,设置的 post 就是 post。如果不是同源,无论设置的什么,都改为 get.
$.ajax({
url: "http://developer.duyiedu.com/edu/testJsonp",
type: "get",
dataType: "jsonp",
success: function (data) {
console.log(data);
},
});14. JSONP 原理
因为我想从一个接口获取一个数据,但是这个接口和当前页面不是同源的。(也就是跨域了)。但是这个接口是支持 JSONP 的。可以用 script 标签,有 src 属性,所以可以发出网络请求
script 标签,虽然可以引用其他域的资源,浏览器不限制。但是,浏览器会将返回的内容,作为 js 代码执行。
如果访问:https://developer.duyiedu.com/edu/testJsonp?callback=asd
把 asd({“status”:”ok”,”msg”:”Hello! There is DuYi education!”}) 作为 JS 代码执行:相当于调用了 asd 方法,传入了一个 json 对象作为参数。但是 asd is not defined。这时候如果定义了 asd 函数,则执行该函数。另外,asd 函数定义的时候可以传一个参数,这个参数就是服务器的返回结果。虽然服务器返回的是 asd({“status”:”ok”,”msg”:”Hello! There is DuYi education!”}) ,但是经过了 asd 函数,所以最终返回{“status”:”ok”,”msg”:”Hello! There is DuYi education!”}
<script>
function asd(data) {
console.log("asd执行");
console.log(data);
}
</script>
<script src="https://developer.duyiedu.com/edu/testJsonp?callback=asd"></script>JSONP 原理:
1. 判断请求与当前页面的域,是否同源,如果同源则发送正常的 ajax,就没有跨域的事情了。
2. 如果不同源,生成一个 script 标签
3. 生成一个随机的 callback 名字,还得创建一个名为这个的方法。
4. 设置 script 标签的 src,设置为要请求的接口。
5. 将 callback 作为参数拼接在后面。
============以上是前端部分================
6. 后端接收到请求后,开始准备要返回的数据
7. 后端拼接数据,将要返回的数据用 callback 的值和括号包裹起来
** 例如:callback=asd123456,要返回的数据为{“a”:1, “b”:2},**
** 就要拼接为:asd123456({“a”:1, “b”:2});**
8. 将内容返回。
============以上是后端部分================
9. 浏览器接收到内容,会当做 js 代码来执行。
10. 从而执行名为 asd123456 的方法。这样我们就接收到了后端返回给我们的对象。
封装 JSONP
var $ = {
ajax: function (options) {
var url = options.url;
var type = options.type;
var dataType = options.dataType;
//判断是否同源(协议,域名,端口号)
//获取目标url的域
var targetProtocol = ""; //目标接口的协议
var targetHost = ""; //目标接口的host,host是包涵域名和端口的
//如果url不带http,那么访问的一定是相对路径,相对路径一定是同源的。
if (url.indexOf("http://") == 0 || url.indexOf("https://") == 0) {
var targetUrl = new URL(url);
targetProtocol = targetUrl.protocol;
targetHost = targetUrl.host;
} else {
// 否则同源
targetProtocol = location.protocol;
targetHost = location.host;
}
//首先判断是否为jsonp,因为不是jsonp不用做其他的判断,直接发送ajax
if (dataType == "jsonp") {
//要看是否同源
if (location.protocol == targetProtocol && location.host == targetHost) {
//表示同源
//此处省略。因为同源,jsonp会当做普通的ajax做请求
} else {
//不同源,跨域
//随机生成一个callback
var callback = "cb" + Math.floor(Math.random() * 1000000);
//给window上添加一个方法
window[callback] = options.success;
//生成script标签。
var script = document.createElement("script");
if (url.indexOf("?") > 0) {
//表示已经有参数了
script.src = url + "&callback=" + callback;
} else {
//表示没有参数
script.src = url + "?callback=" + callback;
}
script.id = callback;
document.head.appendChild(script);
}
}
},
};
//http://developer.duyiedu.com/edu/testJsonp?callback
$.ajax({
url: "http://developer.duyiedu.com/edu/testJsonp",
type: "get",
dataType: "jsonp",
success: function (data) {
console.log(data); // 成功后的回调
},
});15. HTTP 状态码
MDN 更标准的解析
- 200 任何以 2 开头的请求成功并且后台服务器已经返回结果
- 301 以 3 开头的都代表重令项 301 永久性重定向
- 302 临时重定向
- 303 重定向 确认了请求方式,必须是 GET 方法
- 400 错误请求(原因可能是传递的参数类型不对或参数不对)
- 403 以 4 开头的代表客户端 被服务器禁止访问资源: (没有权限)
- 404 页面没有找到 (地址错误)
- 503 服务器错误(服务器宕机了或者代码有误)
16. 什么情况下会遇到跨域,描述一下前端常见处理跨域的几种方式。并封装一个 jsonp 原理
产生跨域的原因:浏览器内部存在的安全机制——同源策略(只能是同源之间才允许数据交互) 不满足同源策略就会产生跨域
不满足同源策略的情况:协议、域名、端口号 其中有一个不相同都算是跨域(不同的域名但是对应相同的 IP 两个域名之间也属于跨域)
跨域问题的解决方案
- JSONP
- CORS
- 服务器代理
JSONP 和 CORS 是怎样实现的?
封装 jsonp
/**
* @params {String} url: 请求地址
* @params {String} data: 请求数据 key=value&key1=value1;
* @params {String} callbackName: 接收响应数据的函数名称
**/
// 把callback当成数据传递更省事
function jsonp(url, data) {
var oScript = document.createElement("script");
oScript.src = url + "?" + data; //地址和数据之间用问号分割
document.body.appendChild(oScript);
// 已经append了,就会插到执行队列,不怕remove
document.body.removeChild(oScript); // 输入的时候不断插入script标签,页面太多的script
}
/* callback和data分开传递
function jsonp(url, data, callbackName) {
oScript.src = url + '?' + data + 'callback' + callbackName;
}*/
function success(data) {
console.log(data);
}
jsonp(
"https://www.baidu.com/sugrec",
"pre=1&p=3&ie=utf-8&json=1&prod=pc&from=pc_web&sugsid=34298,33801,34322,31253,34331,34004,34072,34092,26350,34246&wd=duy&req=2&bs=x&pbs=x&csor=3&pwd=du&cb=success"
);自己可以实现搜索框
17. Web 前端应该从哪些方面来优化网站性能
图解 http
网站性能 —— 时间的问题 ——> 加载时间 (文件的加载基于网络的 )
网络加载时间的问题
- 减小文件的体积 —— 压缩文件 webpack
- 就近取材 —— 使用 cdn 加载
- 使用静态资源缓存
- 网络请求可以使用异步请求资源
渲染的时间问题
- 减少重绘重排
需要构建 domtree + cssTree = 渲染树 renderTree
- 把 script 标签写在最后(不阻碍其他资源加载)
- css 样式通过外部引入的方式实现 并且将 link 标签写在 head 标签下面
- 按需加载(懒加载),预加载(提前加载影响性能)
18. 浏览器端缓存有哪些,并描述他们的区别。
Cookies: 一般用来保存用户的信息比如自动登录。
Session:主要作用是通过服务端记录用户的状态。
浏览器缓存
- cookie
- 存储时间可以设置
- 会携带在网络请求的请求头当中
- 数据量较小 4kb
- 存储数据格式都是字符串
- localStorage
- 存储时间是永久性的 除非手动删除 否则一直存在 URL
- 不会携带在网络请求头当中
- 数据量很大 5m
- 存储数据格式是对象{key: value} 数据对应的数据值要求是字符串 window.localStorage
- sessionStorage
- 存储时间是当前会话
- 不会携带在网络请求头当中
- 数据量很大 5m
- 存储数据格式是对象{key: value} 数据对应的数据值要求是字符串
19. 请描述 TCP 三次握手与四次挥手?
三次握手和四次挥手是传输层中 TCP 协议当中的两个概念
TCP(Transmission control protocol): 传输控制协议
特点:
- 可靠的连接协议
- 面向字节流
- 点对点的连接(一对一,一问一答)
- 全双工通信:双方均可以在任何时刻进行数据交互
(原因: 在两端都设有缓存(发送缓存和接收缓存))
可靠连接的前提条件就是通信双方是均需要有接收和发送信息的能力的
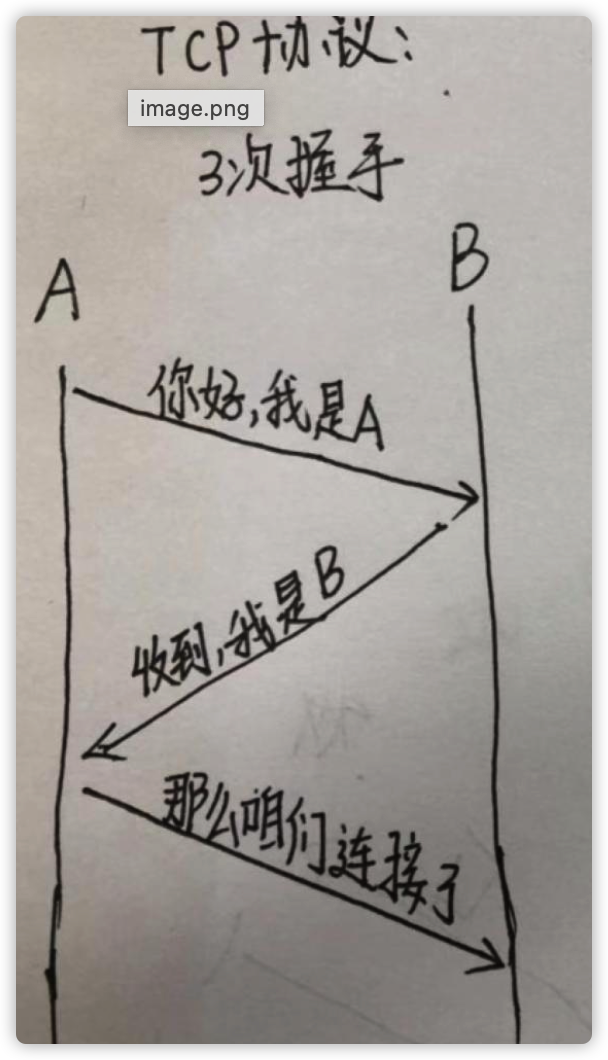
判断前提条件的方法就是先进行建立连接, 建立连接的过程称之为三次握手
A->B
第一次握手 : A -> B (建立连接请求发出)(我要向你发送信息了,你能接收到我的信息吗?)
(如果 B 端接收到这个信息了 可以明确 A 有发送数据的能力)
过程当中的报文标记:SYN = 1 代表建立一个新的连接 当前报文编号为 seq = x
第二次握手: B -> A (B 给 A 发出信息,我收到你的建立连接的信息了, 我可以收到, 你可以收到吗?)
(如果 A 收到这个信息了, A 可以确定 B 可以发出信息 也可以收到信息)
代表的是回应 seq=x 的报文 ack = x + 1
当前的报文编号 seq = y
ack 和 seq 可能相等,因为是独立的。ack 是对对方报文进行回应;seq 对当前这一端发出请求的编号
SYN = 1 代表当前的连接是 B 的新的连接
ACK = 1 代表接收到的连接报文是有效的
第三次握手: A -> B (A 给 B 发出回应信息 我可以接收到你的信息 我开始发了)
(如果 B 接收到这个信息了, B 就明确了 A 有收到信息的能力了)
ACK = 1 : 代表接收到的 B 给出的回应报文是有效的
ack=y+1: 代表回应的是 B 发给 A 的报文编号为 y 的报文
seq = x+1: 代表当前报文的编号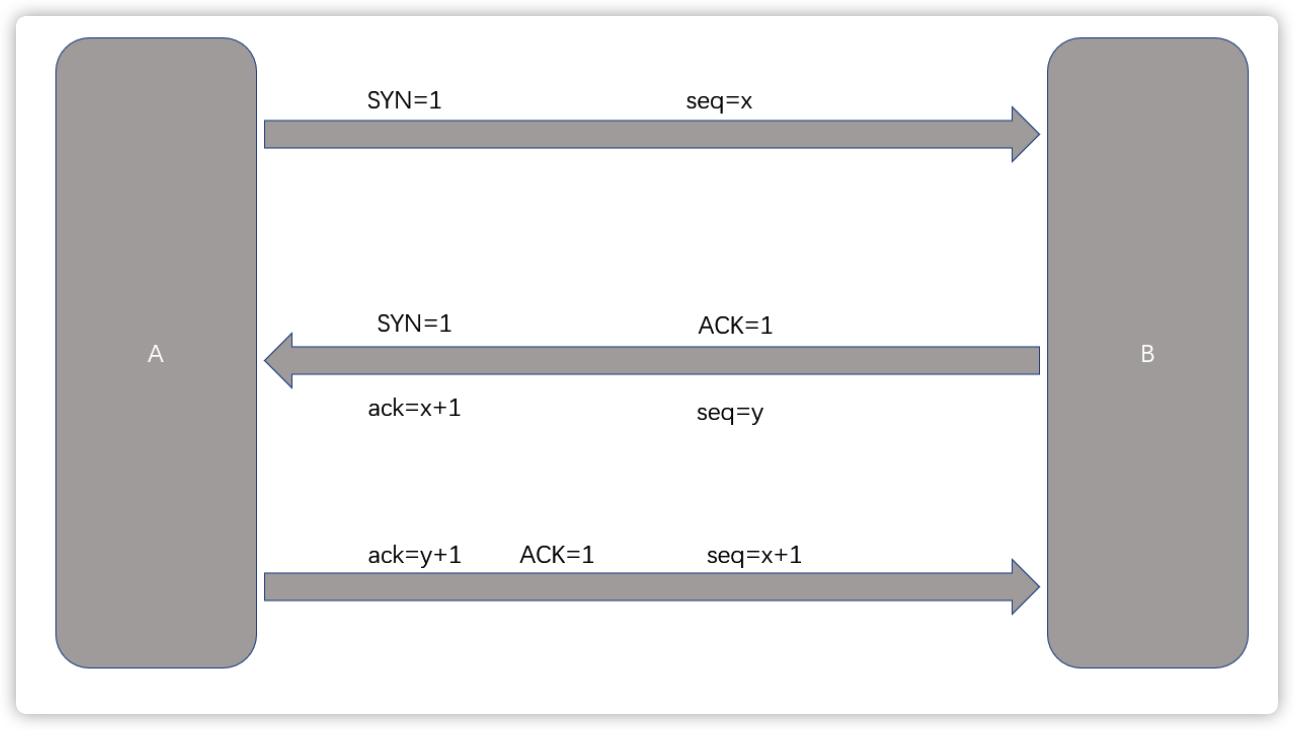
通俗来说:我要给你发信息,你能收到吗?我能收到,但是你能收到吗?我能收到。
只有第三次握手才可以携带数据
接下来数据传递:
A ->B B->A 互相传递数据
A 传递完数据之后需要进行断开连接的操作,断开连接的过程为四次挥手
第一次挥手:
A -> B (A 发出断开连接的请求) (我的数据发完了,我要断开了)
(如果 B 接收到这个请求了,能明确的是 A 已经把所有的数据给完了要断开了)
FIN = 1, seq=u
第二次挥手
B -> A (B 要对 A 断开连接请求进行响应)(我知道你传完了,但是我还没有处理完)
ACK = 1,ack=u+1, seq=v
(如果 A 接收到这个响应了,能明确 B 接收到我的断开连接请求了, 等待断开)
…….继续 B 给 A 发出数据…….
第三次挥手
B -> A (B 要对 A 发出断开连接请求) (我已经把生活费给你了,咱俩分手吧)
FIN = 1, seq=w, ack=u+1, ACK=1
(如果 A 接收到这个断开连接的信息了,能明确 B 已经传递完了,)
第四次挥手
A -> B (A 对 B 断开连接请求进行响应) (我知道你已经传完了,我要断开了)
ACK = 1, ack=w+1, seq=u+1
(如果 B 收到这个信息了,能明确,对方知道我要断开了,接下来 B 断开连接)
第一次挥手可以携带数据,
三次握手过程中可以携带数据么?
跨域问题的解决方案
跨域产生的原因:前端一般会使用 ajax 进行网络交互(客户端和服务器端数据交互)
ajax 的缺点:会受到同源策略的限制
同源策略:就是浏览器提出的一种安全策略。要求只有同源下面的信息才能进行数据交互。
同源: 协议,域名,端口号都相同
http 端口号:默认(隐藏)80
https 端口号:默认 443
客户端和服务器端的网络请求
解决方案:
1.CORS 跨域: cross origin resource sharing 跨域资源共享(只需要后端设置响应头)(IE10 之前不兼容)
Access-Control-Allow-Origin: *
简单请求
- 请求方式只能是get post head
- 请求头字段要求只能有:
Accept
Accept/language
language
Content-Type: 'application/x-www-form-urlencoded' key=value&key1=value1
'text/plain' 纯文本
'multipart/form-data' 二进制文件
对于上述简单请求的跨域只需要在服务端设置响应头
Access-Control-Allow-Origin: *
请求方式的区别: put(一般是对已有数据修改的时候用)
delete(一般是对已有的数据进行删除的时候会用到)
options (自动选择)
head (只进行请求头的发送 不传递请求体)
非简单请求
不是简单请求的请求
对于非简单请求的跨域需要在服务端设置响应头
值中的'*' 代表所有
'Access-Control-Allow-Origin': 'http://localhost:3000',
'Access-Control-Allow-Methods': 'PUT,DELETE',
'Access-Control-Allow-Headers': 'token'- JSONP: json and padding 代表的是返回的数据加上包裹层
‘callback(“{name:”xxx”,age:18}”)’’
原理: script 标签身上的 src 属性 在拿取外部资源的时候是不受同源策略的限制的
缺点:
请求方式只能是 get
返回的数据格式是特殊的
传递的数据大小有限
服务器代理
服务器与服务器之间没有同源限制,浏览器有同源策略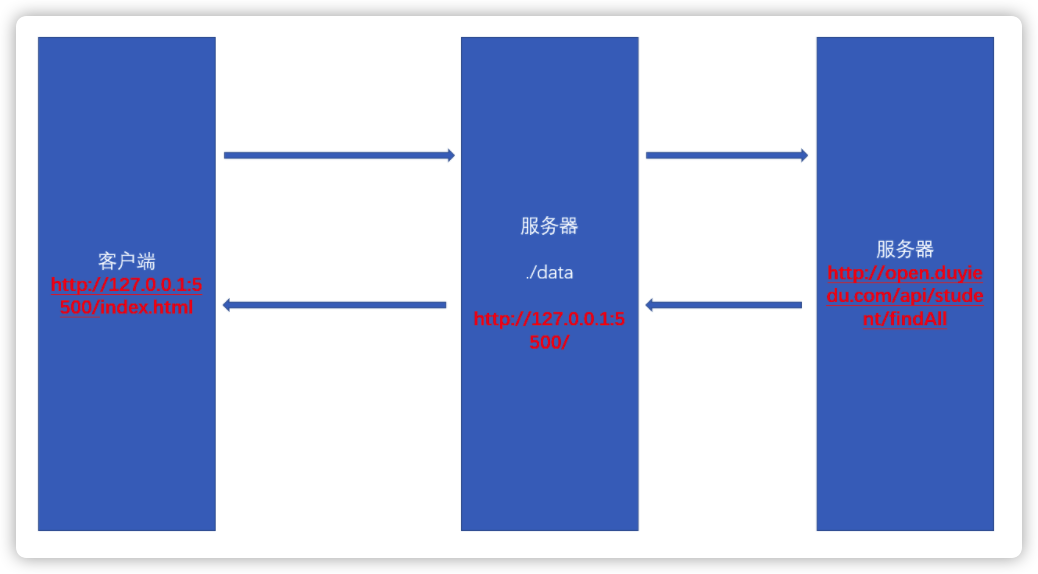
其他跨域
客户端和客户端的跨域:iframe 子窗口之间的跨域问题
eg: h5 postMessage
面试:拥塞控制
一个场景:
当前系统嵌套了一个学生管理系统, 在学生管理系统当中存在一个按钮 这个按钮 代表当前窗口隐藏
<iframe
id="oIfr"
src="http://127.0.0.1:5501/index.html"
frameborder="0"
></iframe>
<script>
var a = 123;
var oIfr = document.getElementById("oIfr");
window.onmessage = function (e) {
console.log(e);
if (e.data.hide) {
oIfr.style.display = "none";
}
};
oIfr.onload = function () {
oIfr.contentWindow.postMessage(a, "http://127.0.0.1:5501");
};
</script>20. TCP 与 UDP 的区别
TCP (传输控制协议) : 为了提供可靠的字节流服务的
1. 以字节流(小的数据包)的形式传递
2. 可靠的连接 有问有答 必须确认一问一答
3. 点对点的
4. 有三次握手和四次挥手的过程
5. 报文的头部信息量大 syn ack...
UDP(用户数据报协议)
- 以数据报文的形式传递
- 不可靠的 不需要确认对方是否收到
- 一对一 一对多 多对多
- 没有三次握手四次挥手
- 报文的头部信息量小
21.http 是什么?
HTTP 是超文本传输协议是一种通信协议,它允许将超文本标记语言(HTML)文档从 Web 服务器传送到客户端的浏览器。
所有 WEB 服务的一个协议,HTTP 协议属于 TCP/IP 协议族的一个子集
HTTP 协议:
对于传递过程当中数据报文格式的约定
用于客户端与服务器端的数据通讯
无状态协议: 没有记忆功能 (不保存之前的记录)
可以做持久连接: (在一端没有发起断开连接请求的时候 就会一直连接着)
HTTP 协议的缺点:
传递的过程是明文传递的 (容易被窃取)
通信双方的身份不能确定 (容易遭遇伪装)
传递的过程当中容易被篡改
安全:
攻击会发生在五层网络模型和物理层之间(客户端和服务端的物理层之间)的过程中
HTTPS = HTTP + (SSL (安全套阶层) + TLS(安全传输协议))
22.http 与 https 的区别
为什么不普遍去用 HTTPS
- 成本开销大
- 加密通信的过程很消耗内存资源以及 CPU 消耗资源
标答:
- 为了数据传输的安全,HTTPS 在 HTTP 的基础上加入了 SSL 协议,SSL 依靠证书来验证服务器的身份,并为浏览器和服务器之间的通信加密。
- http 是超文本传输协议,信息是明文传输,https 则是具有安全性的 ssl 加密传输协议。
- http 的连接很简单,是无状态的;HTTPS 协议是由 SSL+HTTP 协议构建的可进行加密传输、身份认证的网络协议,比 http 协议安全。
23.重排(回流)和重绘是什么?什么情况下会触发重排和重绘。
重排 :重新排列 (页面结构发生变化) 改变 dom 树
重绘: 重新绘制 (样式发生改变) 改变 css 树
offsetHeight,offsetWidth,offsetLeft,offsetTop,scrollHeight,scrollTop
client 不会吗
直播课补充
ajax ===> 封装 ajax 函数 ajax 用来请求资源 可以使页面局部刷新
网络的基础知识
(1). 五层网络模型: 物理层 —》 数据链路层 —-》网络层—》 传输层—》 应用层
duing 邓哥奇遇记
七层网络模型:
应用层: 网络服务与最终用户的一个接口。协议有:HTTP FTP TFTP SMTP SNMP DNS TELNET HTTPS POP3 DHCP
表示层: 数据的表示、安全、压缩。(在五层模型里面已经合并到了应用层)格式有,JPEG、ASCll、DECOIC、加密格式等
会话层: 建立、管理、终止会话。(在五层模型里面已经合并到了应用层) 对应主机进程,指本地主机与远程主机正在进行的会话
[
](http://www.baidu.com:80/)
(3). 三次握手 和 四次挥手 发生在传输层 TCP/IP 协议 TCP 和 UDP
(4). 请求方式: GET(获取数据的时候会用到) POST(新建数据保存的时候用到) HEAD PUT(修改数据的时候会用到) DELETE(删除数据的时候会用到)
(7). 客户端和服务器端的跨域:
<1> jsonp —》 不是 w3c 标准里的
原理: script 标签身上的 src 属性是不受同源策略的限制的
src=”http://www.baicu.com?”
<2> 服务器代理
<3> iframe
iframe + window.name —》 父页面请求子页面的数据 儿子给父亲数据
iframe + location.hash —-》 子页面请求父页面的数据 父亲给儿子数据
iframe + window.postMessage —》 双向请求
<4> CORS —》cross-origin resource sharing 跨域资源共享
后端来设置一个响应头 access-control-allow-origin: ‘http://www.duyiedu.com‘
浏览器先发出请求到服务器 返回的过程中 判断是否是同源的
如果不是同源的会去看响应报文的响应头是否有 access-control-allow-origin: * / 当前页面的域名
w3c 标准里面提出的
<5> document.domain —》 基础域名相同的页面 可以跨域
浏览器将 CORS 请求分成两类:
简单请求和非简单请求,只要同时满足下面两个条件就属于简单请求
( 1 ) 请求的方法只能是 HEAD,GET,POST
( 2 ) HTTP 的头信息不超出以下几种字段
Accept
Accept-Language
Content-Language
Last-Event-ID
Content-Type:只限于三个值 application/x-www-form-urlencoded、multipart/form-data、text/plain
只要不满足以上两个条件就属于非简单请求,浏览器对于非简单请求会进行一次预检
对于简单请求
非简单请求
预检请求
非简单请求指的是对服务器有特殊要求,比如请求方法为 PUT 或 DELETE,或者 Content-Type 字段的类型是 application/json。
非简单请求的 CORS 请求会在通信之前,增减一次 HTTP 查询的请求,成为 “预检”。
浏览器会先询问服务器,当前网页所在的域名是否在服务器许可的名单之中,
以及可以使用哪些 HTTP 请求和头部字段。如果通过服务器的校验,才会发起正式的 XMLHttpRequest 请求,否则就报错
非简单请求的响应头里面必须含有以下字段:
Allow-Control-Access-Origin 必需,表示可以请求的源。
Access-Control-Allow-Methods 必需,表示支持的所有方法,以逗号分隔
Access-Control-Allow-Headers 如果浏览器请求包括 Access-Control-Req 方法,以逗号分隔
Access-Control-Allow-Headers 如果浏览器请求包括 Access-Control-Request-Headers 字段,则 Access-Control-Allow-Headers 字段是必需的。它也是一个逗号分隔的字符串,表明服务器支持的所有头信息字段。
(8) HTTP 请求的发出经历了什么
HTTP 缓存
HTTP 缓存又分为强缓存和协商缓存:
- 首先通过 Cache-Control 验证强缓存是否可用,如果强缓存可用,那么直接读取缓存
- 如果不可以,那么进入协商缓存阶段,发起 HTTP 请求,服务器通过请求头中是否带上 If-Modified-Since 和 If-None-Match 这些条件请求字段检查资源是否更新:
- 若资源更新,那么返回资源和 200 状态码
- 如果资源未更新,那么告诉浏览器直接使用缓存获取资源
你知道 302 状态码是什么嘛?你平时浏览网页的过程中遇到过哪些 302 的场景?
而 302 表示临时重定向,这个资源只是暂时不能被访问了,但是之后过一段时间还是可以继续访问,一般是访问某个网站的资源需要权限时,会需要用户去登录,跳转到登录页面之后登录之后,还可以继续访问。
301 类似,都会跳转到一个新的网站,但是 301 代表访问的地址的资源被永久移除了,以后都不应该访问这个地址,搜索引擎抓取的时候也会用新的地址替换这个老的。可以在返回的响应的 location 首部去获取到返回的地址。301 的场景如下:
Fetch API 与传统 Request 的区别
- fetch 符合关注点分离,使用 Promise,API 更加丰富,支持 Async/Await
- 语意简单,更加语意化
- 可以使用 isomorphic-fetch ,同构方便
对称加密和非对称加密的区别
HTTP2.0 提升有哪些
- cookies 和 session 的区别
- get 和 post 的区别
- Ajax、fetch、axios 的区别
- http 和 https 的区别
- 解释 ajax 的工作原理
https 加密方式
常见 Http 请求头和响应头
几种常见的 content-type
HTTP
- 必考:HTTP 状态码知道哪些?分别什么意思?
- 大公司必考:HTTP 缓存有哪几种?
- 必考:GET 和 POST 的区别
- Cookie V.S. LocalStorage V.S. SessionStorage V.S. Session
集训面试题
什么是服务器
服务器在不同的语境下可能表达了不同的含义:
- 一台独立的计算机
- 一个应用程序
绝大部分使用,作为开发者,通常把服务器看作是一个应用程序
如果一个服务器(应用程序),它仅仅为一个浏览器访问网站服务,我们称它为web 服务器
实际上,目前的 web 服务器和游戏服务器界限已经非常模糊,可以认为,凡是在互联网中提供服务的服务器都是 web 服务器
通常,我们把访问服务器的程序,称之为客户端
实际上,web 服务器不仅限于为浏览器提供服务,还可以为手机 app、小程序、小游戏等常见互联网应用提供服务
常见的 web 服务器有:nginx、apache、iis
在开发阶段,web 服务器往往安装在本地计算机,通常也称之为本地服务器
vscode 有一个 live server 插件,其实它就是一个轻量级的 web 服务器
如何访问服务器
服务器程序可能在本机,也可能在远程,它一定运行在某一台计算机上
要在茫茫互联网中访问到服务器程序,就必须:
- 精确的定位到服务器所在的计算机
- 精确定位到计算机中的服务器程序
- 精确定位到程序中的某个功能
通常,我们使用 url 地址来描述以上 3 个信息url地址全称为Uniform Resource Locator,统一资源定位符,是一个字符串,它的格式如下:
protocol://hostname:port/path?query#hashprotocal: 使用的协议,选择不同的协议,会导致和服务器之间消息交互格式、连接方式不同,大部分都服务器支持 http 和 https 两种协议。如果选择了服务器不支持的协议,会导致访问失败。hostname:主机名,可以是ip、域名ip:每台计算机在网络中的唯一编号,127.0.0.1表示本机- 域名:网络中容易记忆的唯一单词,通过
DNS服务器可以将域名解析成IP,localhost会被解析为127.0.0.1
port:端口号,0~65535 之间的数字,相当于服务器计算机上的房号,使用不同的端口号相当于敲不同房间的门。计算机上的程序可以监听一个或多个端口号,如果访问的端口号有程序被监听,则计算机会将到达的网络访问交给对应的程序来处理- 端口号可以不写,使用默认值
http协议默认值 80https协议默认值 443
path: 一个普通的字符串,该字符串会交给 web 服务器处理,主要用于定位服务- 如果
path为/,则表示根路径,如http://www.baidu.com/的 path 就是/
- 如果
query: 一种特殊格式的字符串,该字符串会交给 web 服务器处理,主要用于向服务器某个服务传递一些信息- 格式为:
属性名=属性值&属性名=属性值
- 格式为:
不同服务器不一样,那百度举例子:https://www.baidu.com/s?wd=html。如果没用query,则https://www.baidu.com/s/html
不同公司给出文档:
path:/api/movie
query:
名字 含义 默认值
page 页码 1
limit 页容量 100
/api/movie?page=2?limit=20
hash:一个普通的字符串,在浏览器的地址栏中,如果 url 其他位置的信息保持不变,仅变动 hash,浏览器不会重新访问服务器,因此通常用于不刷新的页面内跳转
可以看出:
hostname是用于精准定位计算机的port是用于精准定位服务器的protocal是用于告诉服务器使用哪种协议进行传输数据path是用于精准定位服务器上的服务的query是在使用服务的时候传递的额外信息,具体看服务器要求hash是一些额外信息,服务器要不要用具体看服务器要求
示例:分析出下面 url 地址的各部分内容
https://baike.baidu.com/item/HTML?a=1#1注意:url 仅支持 ASCII 字符,如果是包含非 ASCII 字符,会被现代浏览器自动进行编码
例如:https://www.baidu.com/s?wd=http协议
会被编码为https://www.baidu.com/s?wd=http%E5%8D%8F%E8%AE%AE
url 地址不能过长,因为很多浏览器对 url 地址长度是有限制的,chrome 对 url 的长度限制为 8182 个 ASCII 字符
http 协议
我们可以通过 url 地址访问服务器,但是,浏览器和服务器之间的数据到底是怎么交互的,数据的格式是什么,这取决于使用什么协议
最常见的协议,就是 http 协议
http 协议将和服务器的一次交互看作是两段简单的过程组成:请求 request和响应 response
- 请求:客户端通过 url 地址发送数据到服务器的过程
- 响应:服务器收到请求数据后回馈数据给客户端的过程
当 请求-响应 完成后,本次交互结束,如果需要得到额外的服务,则需要重新发送新的请求
同时,http 协议约定了请求的消息格式和响应的消息格式
请求消息格式
请求消息格式有两部分组成:请求头 request headers 和 请求体 request body
请求头
请求头是一个多行文本的字符串
比如我们请求 http://www.baidu.com/s?wd=html, 得到的请求头可能如下:
GET /s?wd=html HTTP/1.1
Host: www.baidu.com
User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/79.0.3945.88 Safari/537.36
...可以看出,该字符串有两个部分组成
- 请求行:请求方法 path 协议
- 请求方法:一个普通的字符串,会被服务器读取到。常见的请求方法:GET、POST,(可以自定义请求方法)
- path:即 url 中的 path + search + hash,服务器可能会用到 path 中的信息
- 协议:协议以及版本号,目前固定为 HTTP/1.1
- 键值对:大量的属性名和属性值组合,可以自定义。
- Host:url 地址中的 hostname
- User-Agent:客户端信息描述
- 其他键值对
请求头描述了请求的元数据信息,这里的元数据信息是指与业务无关的额外信息
当我们在浏览器地址栏输入一个 url 按下回车后,浏览器会自动构建一个请求头,请求方法为 GET,然后向服务器发送请求
请求体
GET /s?wd=html HTTP/1.1
Host: www.baidu.com
User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/79.0.3945.88 Safari/537.36
Content-Type:
...
请求体中的数据包含业务数据的字符串
理论上,请求体可以是任意格式的字符串,但习惯上,服务器普遍能识别以下格式:
- application/x-www-form-urlencoded:
属性名=属性值&属性名=属性值... - application/json:
{"属性名":"属性值", "属性名":"属性值"} - multipart/form-data:使用某个随机字符串作为属性之间的分隔符,通常用于文件上传
由于请求体格式的多样性,服务器在分析请求体时可能无法知晓具体的格式,从而不知道如何解析请求体,因此,服务器往往要求在请求头中附带一个属性Content-Type来描述请求体使用的格式
例如
Content-Type: application/x-www-form-urlencoded
Content-Type: application/json
Content-Type: multipart/form-dataGET 和 POST
<!-- POST请求 -->
<form action="http://www.baidu.com" method="POST" enctype="multipart/form-data">
<p>
账号:
<input name="loginId" type="text" />
</p>
<p>
密码:
<input name="loginPwd" type="password" />
</p>
<button>登录</button>
</form>
<!-- GET请求 -->
<h1>Test</h1>
<a href="./b.html">去页面b</a>虽然 http 协议并没有规定请求方法必须是什么,但随意的请求方法服务器可能无法识别
服务器一般都能识别 GET 和 POST 请求,并做出以下的差异化处理
- 如果是 GET 请求,不读取请求体,业务数据从 path 或 query 中读取
- 如果是 POST 请求,读取请求体,业务数据从请求体中获取,关于请求体的格式,不同的服务器、同一个服务器的不同服务要求不同
在浏览器地址栏中输入 url 地址是不能产生 POST 请求的,可以使用表单提交产生 POST 请求
由于服务器对 GET 和 POST 处理的差异,造成了 GET 和 POST 请求的差异:
- GET 请求一般没有请求体,POST 请求有
- GET 请求的业务数据放在地址中,安全性较差
- GET 请求传递的业务数据量是有限的,POST 是无限的(除非服务器限制)
- GET 请求利于分享页面结果,POST 不行
响应消息格式
和请求类似,响应消息也分为响应头(response headers)和响应体(response body)
响应头
比如我们请求 http://www.baidu.com/s?wd=html, 得到的响应头可能如下:
HTTP/1.1 200 OK
Content-Type: text/html;charset=utf-8
Server: BWS/1.1
...可以看出,该字符串有两个部分组成
- 响应行:协议 状态码 状态文本
- 协议:协议以及版本号,目前固定为 HTTP/1.1
- 状态码和状态文本:一个数字和数字对应的单词,来描述服务器的响应状态,浏览器会根据该状态码做不同的处理。
- 200 OK:一切正常。你好,
我好,大家好。 - 301 Moved Permanently:资源已被永久重定向。
你的请求我收到了,但是呢,你要的东西不在这个地址了,我已经永远的把它移动到了一个新的地址,麻烦你取请求新的地址,地址我放到了请求头的Location中了 - 302 Found:资源已被临时重定向。
你的请求我收到了,但是呢,你要的东西不在这个地址了,我临时的把它移动到了一个新的地址,麻烦你取请求新的地址,地址我放到了请求头的Location中了 - 304 Not Modified:文档内容未被修改。
你的请求我收到了,你要的东西跟之前是一样的,没有任何的变化,所以我就不给你结果了,你自己就用以前的吧。啥?你没有缓存以前的内容,关我啥事 - 400 Bad Request:语义有误,当前请求无法被服务器理解。
你给我发的是个啥啊,我听都听不懂 - 403 Forbidden:服务器拒绝执行。
你的请求我已收到,但是我就是不给你东西 - 404 Not Found:资源不存在。
你的请求我收到了,但我没有你要的东西 - 500 Internal Server Error:服务器内部错误。
你的请求我已收到,但这道题我不会,解不出来,先睡了 - 通常认为,0~399 之间的状态码都是正常的,其他是不正常的
- 200 OK:一切正常。你好,
- 键值对:大量的属性名和属性值组合,可以在服务器响应的时候自定义。
- Content-Type:响应体中的数据格式,常见格式如下
- ·: 普通的纯文本,浏览器通常会将响应体原封不动的显示到页面上
text/html:html 文档,浏览器通常会将响应体作为页面进行渲染text/javascript或application/javascript:js 代码,浏览器通常会使用 JS 执行引擎将它解析执行text/css:css 代码,浏览器会将它视为样式image/jpeg:浏览器会将它视为 jpg 图片attachment:附件,浏览器看到这个类型,通常会触发下载功能- 其他
MIME类型
- Server:web 服务器类型
- Content-Type:响应体中的数据格式,常见格式如下
响应体
响应消息的正文
网络请求
面试题
ajax
不仅仅是浏览器可以发出请求并获得响应,任何具有网络通信能力的程序均可以这样做。
过去,在浏览器中,只有浏览器本身有发送请求的能力,直到 ajax 的出现。
ajax 是一种技术,让 JS 语言在浏览器环境中获得了新的 API,通过该 API,JS 代码拥有了和服务器通信的能力
传统的 ajax 代码如下
var xhr = new XMLHttpRequest(); //创建发送请求的对象
xhr.onreadystatechange = function () {
//当请求状态发生改变时运行的函数
// xhr.readyState: 一个数字,用于判断请求到了哪个阶段
// 0: 刚刚创建好了请求对象,但还未配置请求(未调用open方法)
// 1: open方法已被调用
// 2: send方法已被调用
// 3: 正在接收服务器的响应消息体
// 4: 服务器响应的所有内容均已接收完毕
// xhr.responseText: 获取服务器响应的消息体文本
// xhr.getResponseHeader("Content-Type") 获取响应头Content-Type
};
xhr.setRequestHeader("Content-Type", "application/json"); //设置请求头
xhr.open("请求方法", "url地址"); //配置请求
xhr.send("请求体内容"); //构建请求体,发送到服务器使用 ajax 访问:http://yuanjin.tech:5100/api/movie
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8" />
<meta name="viewport" content="width=device-width, initial-scale=1.0" />
<title>Document</title>
</head>
<body>
<ul id="movies"></ul>
<button onclick="getMovies()">加载电影</button>
<script>
function asyncConnect(url) {
return new Promise((resolve) => {
xhr.onreadystatechange = function () {
//当请求状态发生改变时运行的函数
// xhr.readyState: 一个数字,用于判断请求到了哪个阶段
if (xhr.readyState === 4) {
var obj = JSON.parse(xhr.responseText); // 将json格式的字符串转换为js对象
resolve(obj);
}
};
xhr.open("get", url); //配置请求
xhr.send(null); //构建请求体,发送到服务器
});
}
var ul = document.getElementById("movies");
var xhr = new XMLHttpRequest(); //创建发送请求的对象
async function getMovies() {
var movies = await asyncConnect("http://yuanjin.tech:5100/api/movie");
for (var i = 0; i < movies.data.length; i++) {
var m = movies.data[i];
var li = document.createElement("li");
li.innerHTML = "<img src='" + m.poster + "' /> " + m.name;
ul.appendChild(li);
}
}
</script>
</body>
</html>怎么验证是否登录 cookie
- CORS 需要设置什么头
- 哈西和 history 区别https://juejin.cn/post/6844903625169502216
- ajax 跨域 解决方案 cors 分两种,简单和复杂
- http 缓存 expire, cache-control https://blog.csdn.net/zhouziyu2011/article/details/71312452
- 304 缓存原理 ETag LastModified JSONP 请求特殊的参数名 callbackjq 里面 datatype:”jsonp”JSONP 和普通 AJAX 有什么区别和优缺点?JSONP 支持跨域,支持 POST 请求,支持 patch 请求?axios 拦截器 axios 好好学一下 。拦截器。读一下如何封装 axios 文章如何取消 axios 重复请求
- 说一下 web worker
- HTML5 的离线储存怎么使用,它的工作原理是什么
- 浏览器是如何对 HTML5 的离线储存资源进行管理和加载?



